React Key 与 Diff 算法
一、Key 的使用
React 进行列表渲染时,如果没有给渲染列表的每一个子元素添加唯一的 key 值,就会报错:
const numbers = [1, 2, 3, 4, 5]
const listItems = numbers.map((item) => (
<li>{item}</li>
))
// Each child in a list should have a unique "key" prop.
元素的 key 最好是列表中一个独一无二的字符串。通常用数据中的 id 来作为元素的 key。
不建议使用索引来用作 key 值,因为列表项目的顺序可能发生变化,使用索引作 key 值会导致性能变差,还可能引起组件状态的问题。
二、为什么需要 Key
React 与 Vue 一样存在 Diff 算法,而元素的 key 用于判断元素是新创建的还是被移动的元素,从而减少不必要的元素渲染,因此需要用 key 值为每个元素赋予一个确定的标识。
注意:并不是拥有 key 值就性能越高。举个例子:
列表数据渲染中,在后面插入一条数据,key 作用并不大:
this.state = {
numbers: [111, 222, 333]
}
insertMovie() {
const newMovies = [...this.state.numbers, 444];
this.setState({
movies: newMovies
})
}
<ul>
{
this.state.movies.map((item, index) => {
return <li>{item}</li>
})
}
</ul>
在 diff 算法中,前面的元素不产生创建删除操作,元素有无 key 值意义不大。
另外,如果只是文本内容改变,不写 key 反而性能和效率更高,因为不写 key 是对所有的文本内容进行替换,节点发生变化,而写了 key 则涉及到节点的增删,反而增加了性能的开销。
三、diff 算法的定义
React 通过引入虚拟 DOM 的概念,极大地避免了无效的 DOM 操作,使页面的构建效率提到了极大的提升,而 diff 算法就是更高效地通过对比新旧虚拟 DOM 来找出真实 DOM 变化之处。
传统 diff 算法通过循环递归遍历整棵树的节点然后进行比较,效率低下,算法复杂度达到 O(n³),而 React 将算法进行了优化,复杂度降为 O(n),两者效率差距如下图:
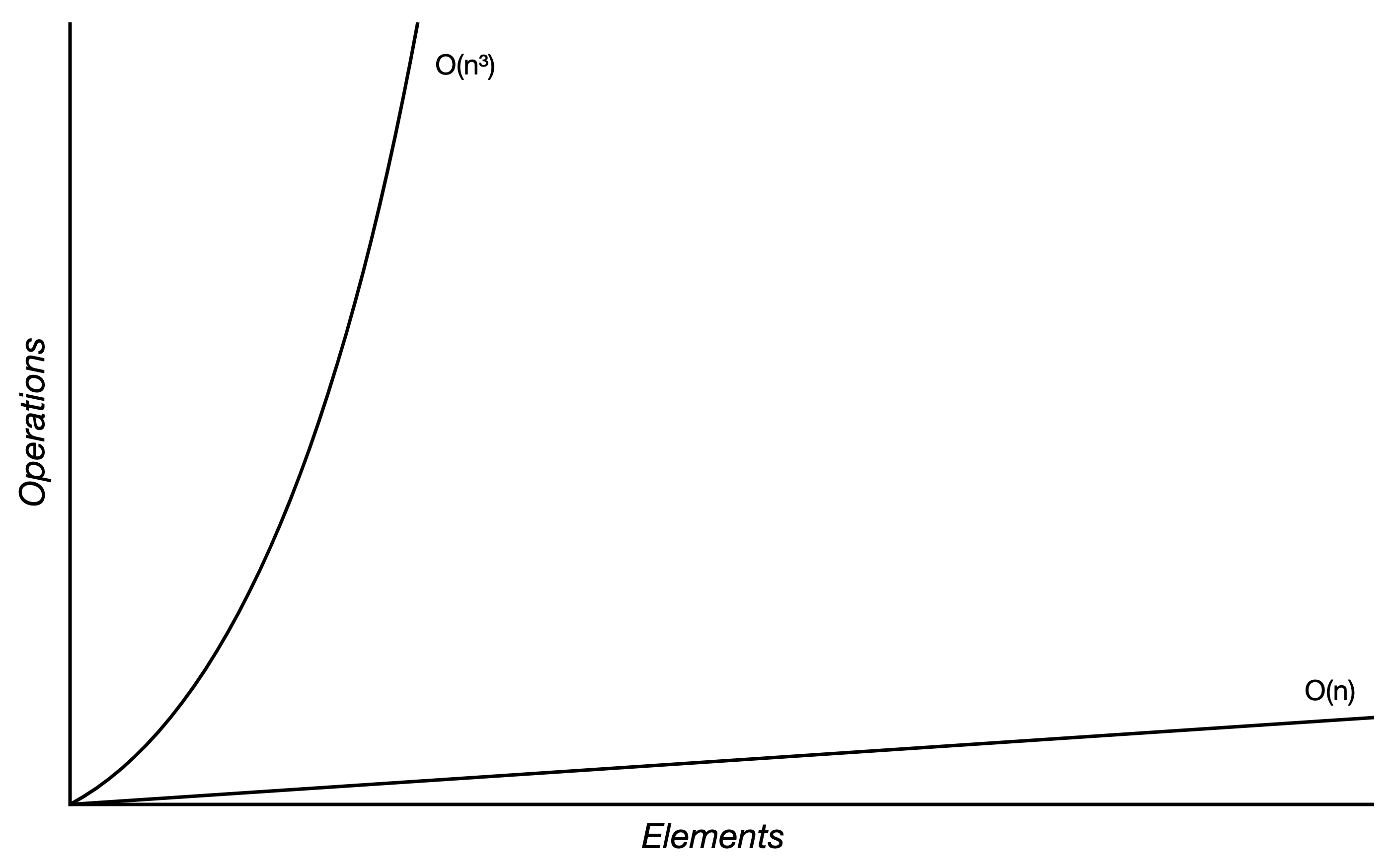
上面的 O(n³) 和 O(n) 是怎么算出来的呢?
React 用三大策略将 diff 算法的复杂度从 O(n³) 降为 O(n):
策略一(tree diff)
只对同一层级节点进行比较,因为 Web UI 中 DOM 节点跨层级的移动操作很少,可以忽略不计。
策略二(component diff)
两个不同类型的元素会产生出不同的树形结构,如果元素由
<div>变为<p>,React 会销毁<div>及其子孙节点,并新建<p>及其子孙节点。策略三(element diff)
对于同一层级的一组子节点,通过唯一 key 值进行区分。
四、React diff 优化原理
1、tree 层级
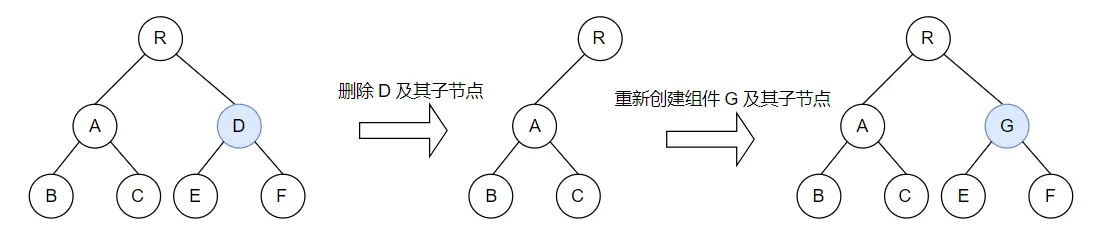
只对同一层级的节点进行比较,DOM 节点跨层级的操作不做优化:
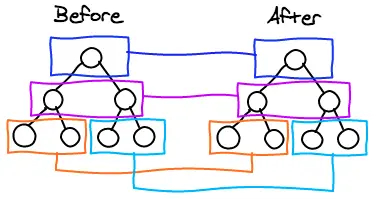
只有删除、创建操作,没有移动操作,如下图:
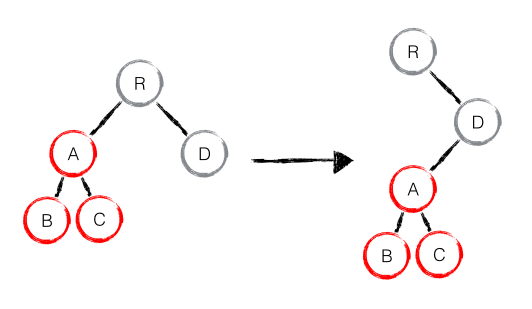
React 发现新树中,R 节点下没有了 A 节点,则直接删除 A 节点,然后在 D 节点下创建 A 节点及其下属节点,该操作中只有删除和创建操作。
2、conponent 层级
如果是同一类型的组件,则会继续往下进行 diff 运算(可以通过 shouldComponentUpdate() 来控制是否对该组件进行 diff 运算),如果不同类型,则直接删除这个组件下的所有子节点,创建新的:
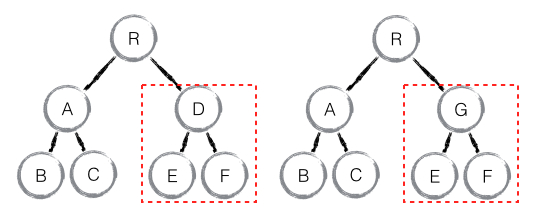
当 component D 换成了 component G 后,即使两者的结构相同,也会将 D 删除再重新创建 G。这是因为基本不存在两个不同类但组件结构相同的情况,如果有,只能证明代码复用性不足,需要优化。
3、element 层级
对于同一层级的一组子节点,通过唯一 key 值进行区分。
当节点处于同一层级时,React diff 提供了 3 种节点操作:
- INSERT_MARKUP (插入)
- MOVE_EXISTING (移动)
- REMOVE_NODE (删除)
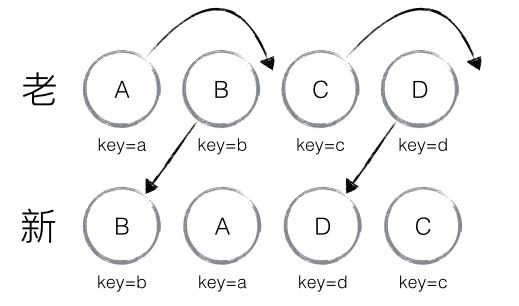
举个例子,对以下一组节点进行处理:
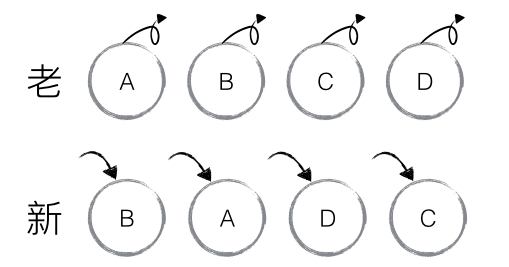
通过 key 值可以准确发现新旧集合中的节点都是相同的节点,因此无需对节点进行删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置即可。