JS 字符串与数组进阶
一、字符串与数组
JS 中的字符串和数组很相似,都属于类数组。
例如下面两个值:
var a = "foo"
var b = ["f", "o", "o"]
1、可变与不可变
JS 中字符串是不可变的,而数组是可变的。
并且 a[1] 在 JS 中并非总是合法语法,在老版本的 IE 中就不被允许。正确的方法应该是 a.charAt(1)。
字符串不可变是指字符串的成员函数不会改变原始值,而是创建并返回一个新的字符串。而数组的成员函数都是在其原始值上进行操作。
var a = "foo"
c = a.toUpperCase()
a === c // false
a // "foo"
c // "FOO"
2、共有属性与方法
字符串和数组都有 length 属性、 indexOf() 和 concat() 方法:
var a = "foo"
var b = ["f", "o", "o"]
a.length // 3
b.length // 3
a.indexOf("o") // 1
b.indexOf("o") // 1
var c = a.concat("bar") // "foobar"
var d = b.concat(["b", "a", "r"]) // ["f","o","o","b","a","r"]
但这并不意味着字符串是“字符数组”,比如:
var a = "foo"
var b = ["f", "o", "o"]
a[1] = "O"
b[1] = "O"
a // "foo"
b // ["f","O","o"]
3、用数组的方法处理字符串
许多数组函数用来处理字符串很方便。虽然字符串没有这些函数,可以通过“借用”数组的非变更方法来处理字符串:
var a = "foo"
a.join // undefined
a.map // undefined
var c = Array.prototype.join.call(a, "-")
var d = Array.prototype.map.call(a, function (v) {
return v.toUpperCase() + "."
}).join("")
c // "f-o-o"
d // "F.O.O"
另一个不同点在于字符串反转。
数组有一个字符串没有的可变更成员函数 reverse():
var a = "foo"
var b = ["f", "o", "o"]
a.reverse // undefined
b.reverse() // ["o","O","f"]
b // ["f","O","o"]
因为字符串是不可变的,所以无法“借用”数组的可变更成员函数
一个变通的办法是先将字符串转换为数组,待处理完后再将结果转换回字符串:
var a = "foo"
var c = a.split("").reverse().join("")
c // "oof"
这种方法简单粗暴,但对简单的字符串却完全适用。
如果需要经常以字符数组的方式来处理字符串的话,倒不如直接使用数组。这样就不用在字符串和数组之间来回折腾。可以在需要时使用 join("") 将字符数组转换为字符串。
二、“稀疏”数组
“稀疏”数组(sparse array),即含有空白或空缺单元的数组。
var a = []
a[0] = 1
// 此处没有设置 a[1] 单元
a[2] = [3]
a // [1, empty, [3]]
a[1] // undefined
a.length // 3
上面的数组 a 中包含了一个的“空白单元”(empty slot)
a[1] 的值为 undefined,但这与将其显式赋值为 undefined(a[1] = undefined)还是有所区别:
var a = []
a[0] = 1
a[1] = undefined
a // [1, undefined]
a[1] // undefined
数组通过数字进行索引,但有趣的是它们也是对象,所以可能包含字符串键值和属性(但这些并不计算在数组长度内):
var a = []
a[0] = 1
a["foobar"] = 2
a // [1, foobar: 2]
a.length // 1
a["foobar"] // 2
a.foobar // 2
如果字符串键值能够被强制类型转换为十进制数字的话,它们就会被当作数字索引来处理:
var a = []
a["6"] = 42
a // [empty × 6, 42]
a.length // 7
在数组中加入字符串键值/属性并不是一个好主意。建议使用对象来存放键值/属性值,用数组来存放数字索引值。
三、伪数组
1、什么是伪数组
伪数组满足以下条件:
- 拥有 length 属性,索引是非负整数。
- 不具有数组的方法。
实际上伪数组就是一个对象。
let e = {
length: 3,
"0": 1,
"1": 'gzc',
"2": 'szc'
}
for (var i = 0; i < e.length; i++) {
console.log(e[i])
}
e instanceof Array // false
e instanceof Object // true
2、伪数组的判断方法
2-1、使用 isArray 判断
Array.isArray(fakeArray) === false
Array.isArray(arr) === true
2-2、封装一个 isArrayLike
这是《JavaScript权威指南》上判断伪数组的方法:
function isArrayLike(o) {
if (o && // o is not null, undefined, etc.
typeof o === 'object' && // o is an object
isFinite(o.length) && // o.length is a finite number
o.length >= 0 && // o.length is non-negative
o.length === Math.floor(o.length) && // o.length is an integer
o.length < 4294967296) // o.length < 2^32
return true // Then o is array-like else
return false // Otherwise it is not
}
3、常见的伪数组
3-1、arguments
(function () {
console.log(typeof arguments) // 输出 object,它并不是一个数组
}())
3-2、获取的 DOM 对象的数组
let f = document.querySelectorAll('a')
4、伪数组转数组
4-1、ES5 转换方式
let args = [].slice.call(arguments) //collection
// arguments 只能在函数体内使用
// ES6 已经废弃 arguments 的使用
let imgs = [].slice.call(document.querySelectorAll('img')) // NodeList
4-2、ES6 转换方式
let args = Array.from(arguments)
let imgs = Array.from(document.querySelectorAll('img'))
5、数组跟对象的区别
- 数组是有索引的。
- 数组有长度,对象无长度。
三、内存模型与 JS 数组的特殊之处
1、连续内存
数组是会被分配的一段连续内存,如图:

当向数组最后 push 元素 6 时,只需要将后面的一块内存分配给 6 即可。
但 unshift 则不同,数组为了保证连续性,头部之后的元素需要依次向后移动。
unshift 的本质类似于下面的代码:
for (var i = numbers.length; i >= 0; i--) {
numbers[i] = numbers[i - 1];
}
numbers[0] = -1;
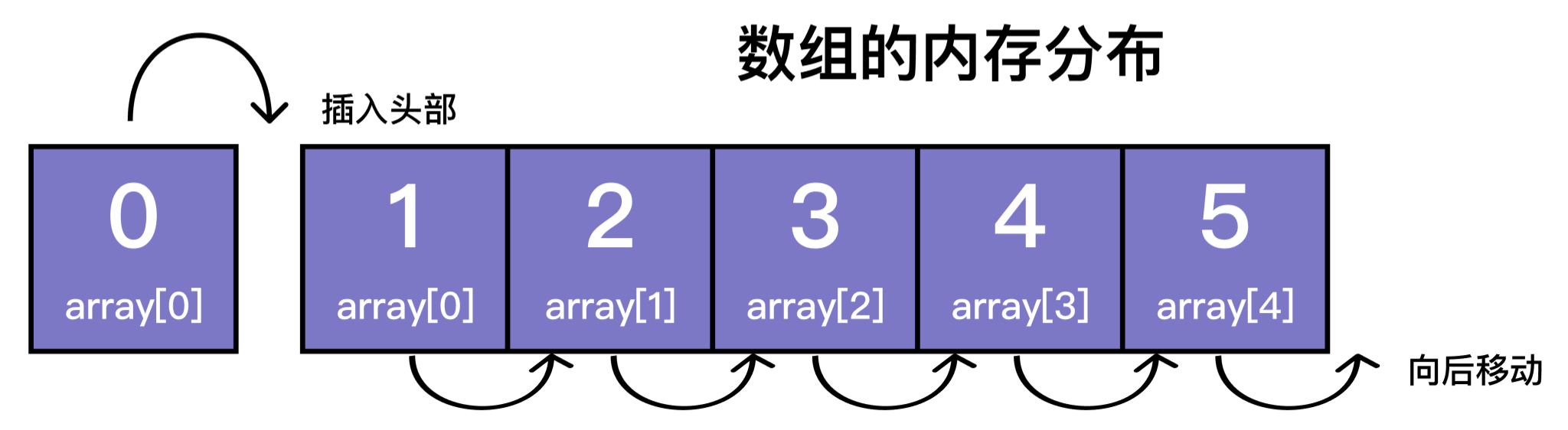
由于 unshift 触发所有元素内存后移,导致性能远比 push 差。
这是因为数组是被储存为一块连续内存导致的,这就造成数组『插入』或『删除』时,其他元素为了保持一块连续的内存都不得不产生大量元素位移,影响性能。
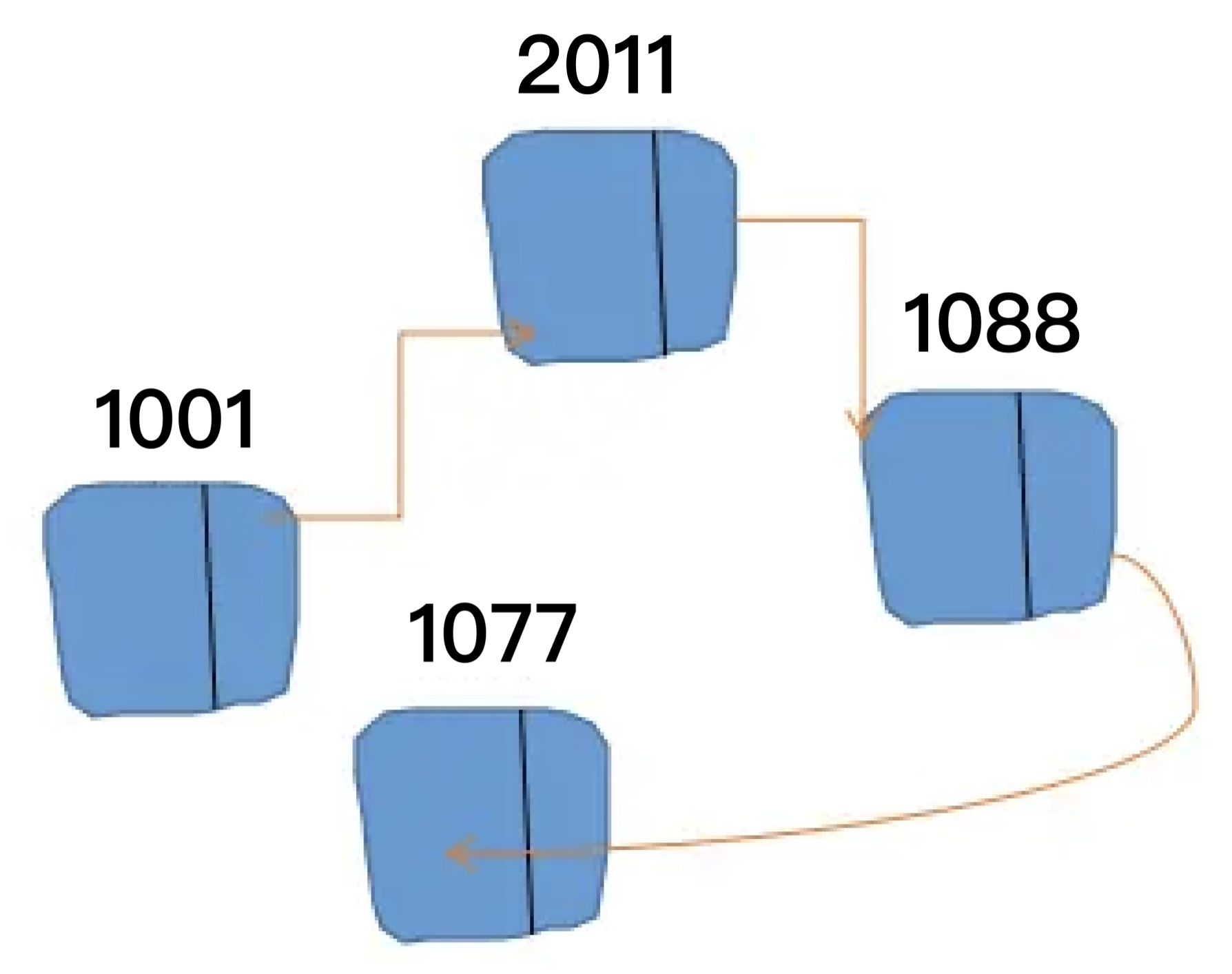
2、非连续内存
非连续内存的数组用的是类似哈希映射的方式存在,比如声明了一个数组,它被分配给了 1001、2011、1088、1077 四个非连续的内存地址,通过指针连接起来形成一个线性结构,那么当我们查询某元素的时候其实是需要遍历这个线性链表结构的,这十分消耗性能。
而线性储存的数组只需要遵循这个寻址公式,进行数学上的计算就可以找到对应元素的内存地址。
a[k]_address = base_address + k * type_size
非线性储存的数组其速度比线性储存的数组要慢得多。
3、为什么 JS 数组不是真正的数组
数组的定义:数组(Array)是由相同类型元素(element)的集合所组成的数据结构,分配一块连续的内存来存储。
而 JavaScript 的数组不一定是连续内存,是否连续内存取决于数组成员的类型,如果数组的成员类型一致则会分配连续内存,如果数组成员类型不一致,则是非连续内存。
这也是建议 JS 数组成员要尽量保持同一类型的原因。点击查看 V8 引擎下数组的底层实现